Disagreement as information: the human role in AI-augmented research

Justin Strharsky
Head of Research, AITAI
At the Australian Institute of Transformation and AI (AITAI), we've been building a pipeline that classifies Australian news articles about AI by topic and sentiment. This is part of our living evidence base on how AI is being discussed, adopted, and debated in Australia. Much of the heavy lifting is done by an LLM-based classifier working through volumes no human team could process manually.
But before sharing any of the output, we had to answer a fundamental question: Can we trust it?
The standard answer is inter-rater reliability (IRR). Two humans independently classify the same articles and we measure their agreement using Cohen's Kappa. We then do the same between humans and the AI. If the AI agrees with humans about as much as humans agree with each other, we have a defensible basis for scaling. We set Kappa thresholds in advance, based on content-analysis standards.
Pretty straightforward in theory. Less so in practice.
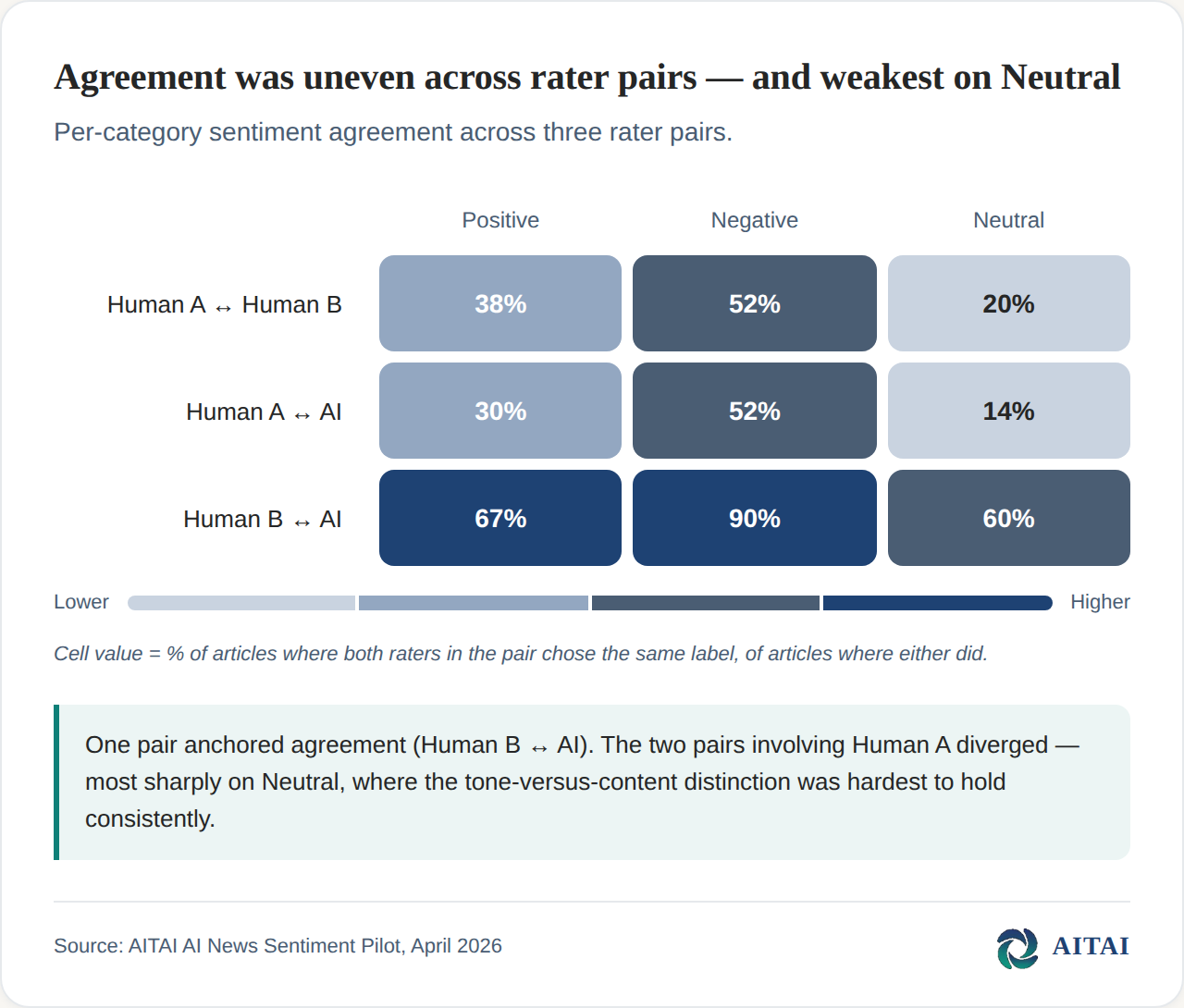
Turns out AI was the easy part
Human–AI agreement was already in a reasonable range on our first full IRR test. The challenge wasn't getting the AI to agree with humans. It was getting two humans to agree with each other.
One coder was broadly aligned with the pipeline: consistent, repeatable, close to the codebook. The second, however, was systematically different, and disagreed with both the first coder and the AI on a meaningful fraction of articles. Our human–human Kappa was below threshold. And because our standard is that human–AI agreement should meet or exceed human–human agreement, the entire pipeline was blocked behind the human disagreement.
Reconciliation as forcing function
The obvious hypotheses — misread codebook, category ambiguity, some type of bias — couldn't be distinguished from the numbers alone. To find the root cause, we introduced a reconciliation step. We asked each coder to return to the disputed articles, re-read the codebook, and articulate their reasoning in writing. The goal wasn't to "defend" a choice, but to make the underlying logic explicit.
The coder who had disagreed most often, on careful re-reading and reflection, arrived at different judgements for a substantial share of the disputed articles. Their revised codings would likely have brought us over the threshold.
It might be tempting to conclude that one coder was simply "worse" at the task. But that would cause us to miss something significant.
We discovered that the classification task was partly underdetermined. A news article about an AI system causing harm can genuinely read as a Risk & Ethics story, a Policy & Regulation story, or an Innovation & Research story, depending on where the reader's attention lands. Deciding which it's primarily about is a judgement call. The codebook exists to make that judgement consistent, but a codebook is only as good as the shared interpretation behind it.
The sentiment dimension made this especially visible. Our schema defined sentiment by content — whether the article was about positive or negative developments — not by tone. A sober report of a major AI-related job loss should be coded negative; an enthusiastic write-up of a successful deployment should be coded positive. One coder applied this consistently. The AI applied it consistently. The second human coder was implicitly weighting tone, and the effect concentrated on a single label: even-handed articles about harmful events drifted toward "Neutral." This wasn't a refusal to follow the codebook. Holding the content-versus-tone distinction in mind article after article is cognitively demanding, and Neutral is where the tone-reading heuristic offers an easy out.
Where automation has a genuine advantage
This points to something specific about what AI automation can contribute to research. Humans tire. Careful distinctions that were crisp on article five become blurry by article fifty. Automated systems don't drift that way. An agentic pipeline can consult the codebook on every article and apply the same decision rule on the thousandth as well as on the first.
And where it doesn’t
This doesn’t mean simply "AI is better." LLMs have their own variability: stochastic outputs, prompt sensitivity, new versions. We can engineer AI consistency, but it doesn’t come for free. Human variation and AI variation have different sources, and both must be managed.
What this means for AI-augmented research
Two things we took from this:
Human-human IRR is a diagnostic tool, not just a metric. It's a forcing function for codebook completeness and clarity. Going straight to human–AI testing might have produced acceptable numbers that actually rested on unarticulated, divergent interpretations. Human variability isn't a defect, it’s information that highlights where a codebook needs more worked examples.
Second, the value of a human-AI hybrid pipeline is in leveraging the strengths of both. Once humans have done the hard interpretive work of building a codebook that captures shared understanding, the AI makes reliability scalable across volumes no human team could handle.
This matters because the research output is ultimately meant for humans to consume. In fact, not just to consume, but to act on. A government advisor needs to trust that a report on AI-driven job losses is coded as 'Negative' based on its real-world impact, rather than being lost in 'Neutral' simply because the journalist wrote with clinical detachment. If we want to produce evidence that informs real-world decisions, it must be more than 'accurate' by a machine's standards. It must be clear and trustworthy to the people consuming it.
We’ll be publishing specific findings from this research stream soon. But the methodological lesson we learned already seems clear and worth sharing now. In building AI-augmented research, the human stage is where we spend the most time, and it's where the most time needs to be spent to ensure the results are worth acting on.