AI in the Australian News: what 339 articles told us (and why we don't trust the results yet)

Justin Strharsky
Head of Research, AITAI
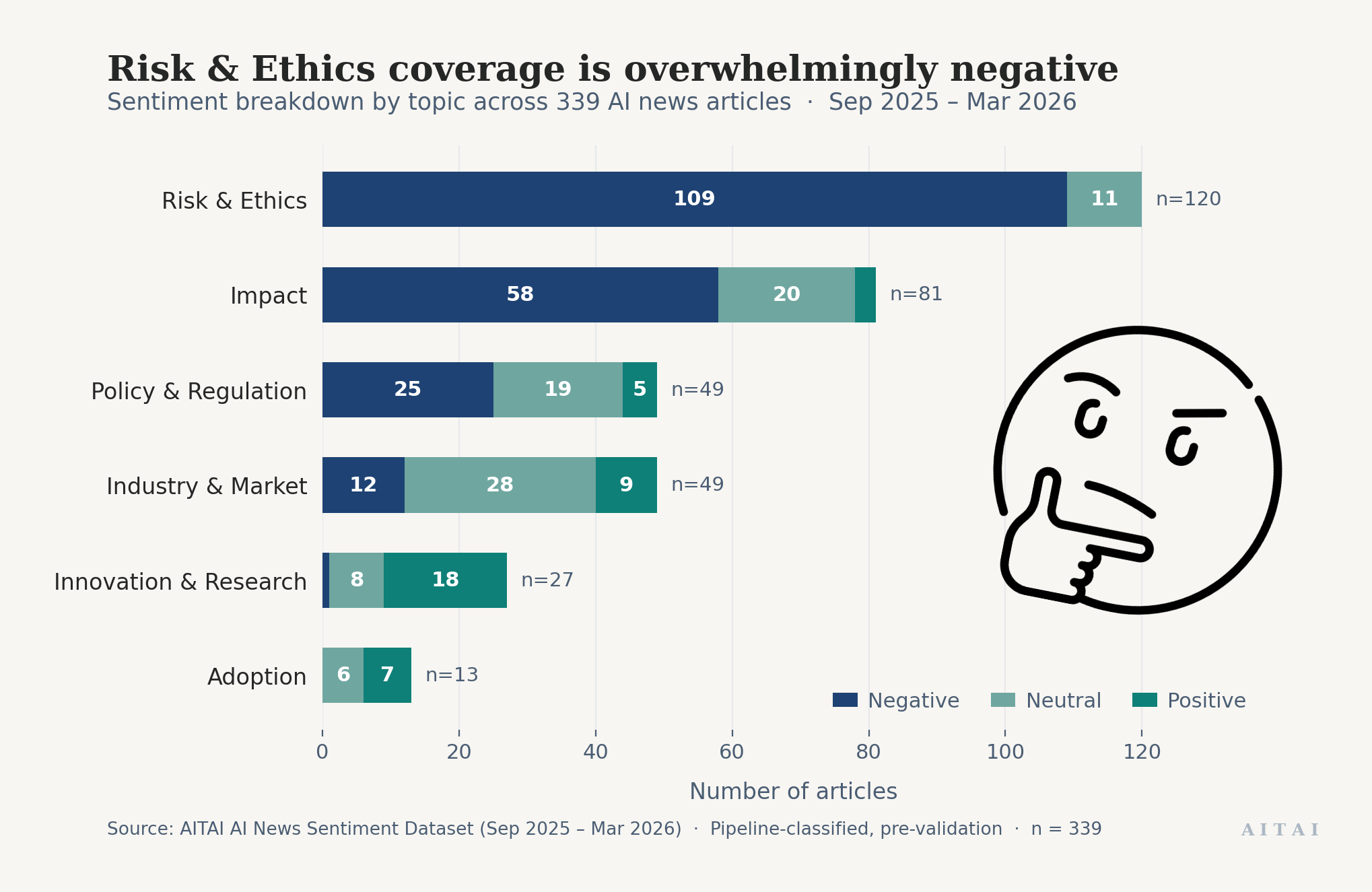
Last week, our small team of researchers built an AI pipeline that ingested 339 full-text news articles from the Sydney Morning Herald, ABC News, The Guardian Australia, and SBS News, covering six months of AI reporting from September 2025 through March 2026. Every article was classified by topic and sentiment.
Then two (human) team members independently classified a sample of 25 articles using the same schema. They agreed about half the time.
An agreement rate about 50% is roughly what you'd expect from chance. That's a problem. And the way we caught it has implications beyond media research.
What we built
The pipeline is straightforward in concept. Articles are ingested from source, processed through an automated classifier that assigns topic categories (adoption, impact, policy and regulation, risk and ethics, innovation and research, and industry and market) and sentiment (positive, neutral, or negative), and stored in a structured format for analysis. A traditional research team doing manual content analysis at this scale might budget weeks for the coding alone. This pipeline did it in days.
But the pipeline is only the first layer. The second layer is human validation. Independent classification of samples by team members, with formal agreement rates computed to test whether the schema is precise enough to produce consistent results. The third is a refinement loop: when validation fails, the schema gets tightened and the pipeline runs again.
Where it broke
The pipeline surfaced a pattern that looked striking at first glance. Risk & Ethics articles were 91% negative, with not a single positive classification.
But the inter-rater test told us we couldn't trust those numbers yet.
Consider articles about AI risk. It seems natural that these would all be negative, but a story about a company that identified an AI risk early and mitigated it before anything went wrong would be a risk article with positive sentiment. So would an article about AI being used to assess the risks of AI. The fact that zero out of 120 risk articles were classified as positive might mean Australian media genuinely never frames risk positively. Or it might mean our definitions aren't giving the classifier enough guidance to separate "this article is about risk" from "this article feels negative."
We can't distinguish between those two explanations until the schema is tight enough that two humans, working independently, reach the same conclusion.
What we learned
In traditional research, you might not catch this until months into a project, after the codebook is locked, the manual coding is done, and the analysis is written up. Fixing it at that point means recoding hundreds of articles.
We set out to classify Australian media coverage of AI. Instead we generated a set of observations about how to build AI systems for research. It turns out these observations also matter well beyond our specific use case.
Automation surfaces problems faster, but only if you design for oversight. The speed of the pipeline didn't just accelerate data processing. It accelerated the discovery that our instrument was flawed. That only happened because we built human validation into the first sprint, not as an afterthought after the analysis was written up. Most enterprise AI projects incorporate evaluation late, if at all. The earlier you build it in, the cheaper the mistakes are.
Imprecise definitions break AI systems. The classification problem we hit is a version of something every organization deploying AI encounters: the system appears to work until you realize the categories it operates on mean different things to different people. Our two researchers weren't disagreeing about what AI can do. They were disagreeing about what "risk" means and what "negative" means when applied to a news article. That's a semantics problem, not a technology problem. It's the same class of problem that derails enterprise AI projects when the labels, taxonomies, or business rules feeding a model aren't precise enough.
What we're doing about it
The team is now refining the classification schema by tightening the definitions of topic categories and sentiment to ensure they capture genuinely independent dimensions.
Two team members will independently reclassify a fresh sample using the updated schema, and we'll recompute formal agreement rates to measure whether the refinement worked.
Building automated research infrastructure
This sprint was the first proof-of-concept for AITAI's automated research pipeline: infrastructure designed to build a living evidence base about AI adoption and impact in Australia.
Ingesting and classifying 339 articles in a single sprint demonstrates what the automated pipeline can do. Catching the topic–sentiment overlap and refining the schema demonstrates why human oversight remains essential. Together, they point towards a research cycle fast enough to inform important decisions.
If you're working on AI adoption research, AI policy, or media analysis in Australia, we'd welcome a conversation.